Organizations often possess a lot of data that’s being stored in unstructured formats. Most of the time, this involves data that people were able to enter as free text, such as e-mails, call center logs, presentations, manuals etc.
In this example, I show what I used to parse resume and CV documents and extract the skills listed by my consultant colleagues at AE. This helped us move from manually wrangling .docx files to a new UX-friendly custom web app. With everyone’s skills are already filled in along with suggestions to the user for new skills, the transition to use the new tool is a lot smoother.
This story was previously published in 2016 on my employer’s blog here
My colleagues have a lot of experience in various technologies and methodologies. While we like to help each other out with issues or by answering questions, it’s not always easy to keep track of who we can contact for a certain question. These skills could be found in the CV documents, but these files are not easily searchable in a structured way.
Next to that, we’d also like to get an overview of how our colleagues relate to one another: which people have the same skills and are there potential gaps within the organization?
Before we can visualize this information we’ll need to extract it and clean it.
Data gathering and cleaning
Each consultant has their own CV in a Word document where they’ve listed all of their skills in a bulleted list. That means we can automatically look through these CVs, extract the skills and then clean up the data.
First, we need to convert the Word documents to a format that allows for automated parsing. To complete this step, I used a PowerShell script to fetch the most recent version of each CV from a shared drive (and exclude files marked as old or in a different language) and to transform it to the XML-representation, with the help of Apache Tika.
$files = dir dump $Directory -rec -exclude “* ned*”,"*old*","* nl*","*.pdf"."*.xls","*-NED*" $files | group directory | foreach { $a = @($_.group | sort {[datetime]$_.lastwritetime} -Descending)[0] $b = “xml\” + $a.Directory.Name + “.xml” echo $a" to “$b; java -jar tika.jar -r $a.FullName >> $b }
This generates an XML-file for each colleague:

The skills can be found as
elements between the chapters “Professional Skills” and “Professional Experience”. To extract these elements, we can can target them with XPATH queries. For this task I used R.
Further down this blog post, we’ll also use R to visualize the skills, but for now we only use the XML package to parse the Word documents. It seemed several different templates were used throughout the years, which is why the XPATH query tries different matches when it can’t find anything:
doc = xmlInternalTreeParse(x,addAttributeNamespaces = FALSE) src = xpathSApply(doc, “(//p[following::p[contains(translate(text(), ‘PROFESINALXRC’, ‘profesinalxrc’),‘professional experience’)] and preceding::p[contains(translate(text(), ‘PROFESINALK’, ‘profesinalk’),‘professional skills’)] and (@class=‘opsomming’ or @class=‘opsom2’)])",xmlValue,simplify=TRUE)
This results in a large list of skills with several problems. Skills have have been combined in one bullet point (e.g. “R & SAS”), descriptions have been added (e.g. “experienced in…”), the same tool is mentioned in various ways (e.g. “Microsoft Systems Center”, “MSSC”, “MS Systems Center” …), sometimes even with version numbers, and so on.
This list has to be cleared further to streamline the notations and to remove any clutter. For this I jumped to Open Refine. In R I exported the list of extracted skills for each consultant to a CSV-file in which each row consists of two columns: the name of the person and a single skill. Next, I performed the following actions on the second column:
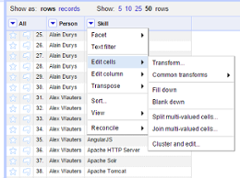
- Split on special signs such as ‘(‘, ‘&’, ‘)’, …
- Remove spaces before and after skills
- Merge similar skills and convert to 1 specific notation
- Delete skills which we don’t use for our analysis.
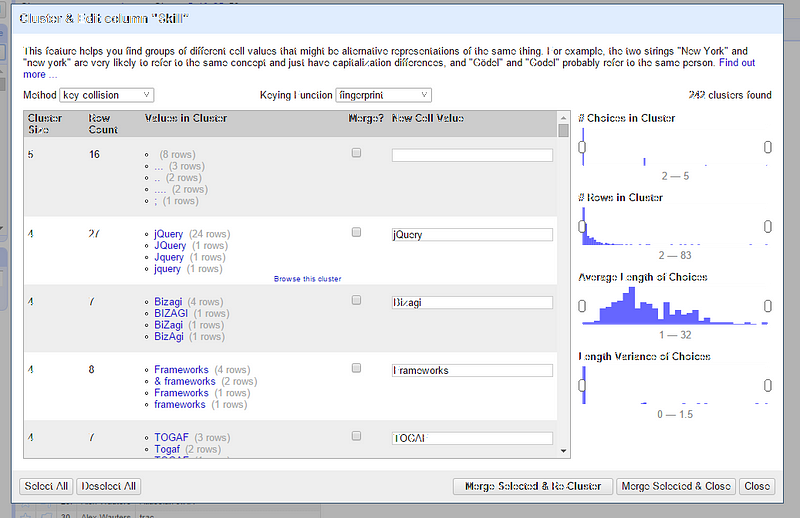
Open Refine contains a number of helpful operations to aid in this process, such as automatic clustering of similar skills, the ability to sort on the most common skills etc. The result of this step is to create a clean list of skills for each consultant, which we can then use to search and analyze.
Data analysis and visualization
Now that we’ve got a clean set of persons and skills, we want to know which consultants have similar skills and visualize that info in an intuitive way.
We’ve chosen to do this using the Multidimensional Scaling (MDS) technique: consultants are spread out across two dimensions, with consultants with more skills in common placed closely together whereas consultants with fewer skills in common are placed further apart, with a logarithmic smoothing function applied
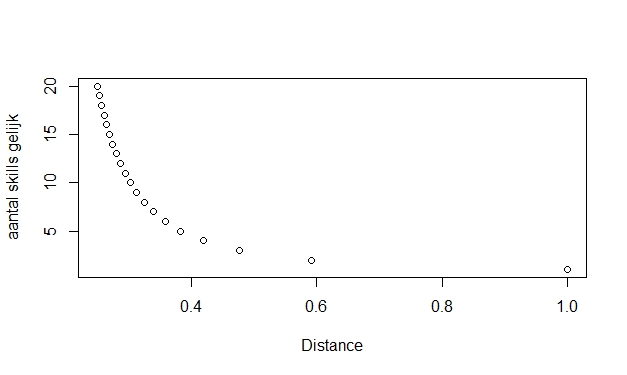
To calculate the MDS results, we once again turned to R, this time with the stats package. We visualized the result using D3.js, a JavaScript library for data visualization, as shown here below. This way, we can gain insight into which consultants have similar skills, which groups/clusters we can define, which consultant profiles overlap almost completely, etc. The color denotes which team (‘hive’) the person is in.
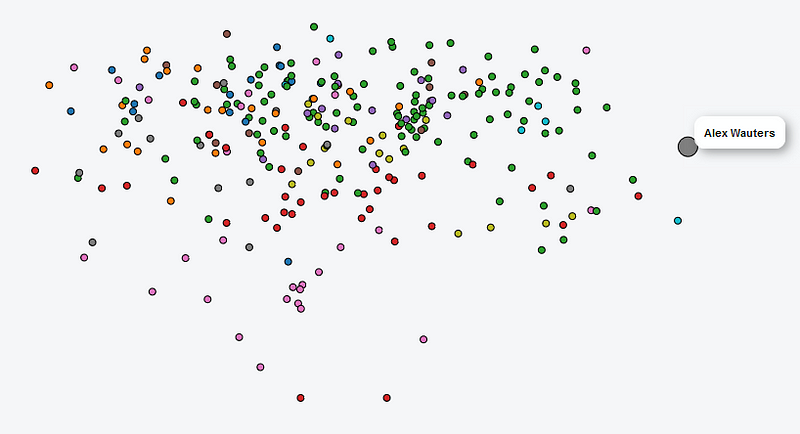
Operationalization
To make the cleaned-up list fully searchable, we used this list for the launch of an application we call Sk!lld.
The initial idea and implementation for Sk!lld came from an internal hackathon. Sk!lld is a web app everyone at the company can use to find people based on their skills and in which consultants can keep their CV up to date and stop wrangling different MS Word documents. The skills were added to the user profiles, after which they could be searched through Apache Solr.

Our colleagues can now keep their skills up to date inside the app and even indicate which skills they would like to develop.
Sk!lld also makes suggestions based on your search terms or based on the skills you’ve already got on your profile. We get these suggestions by applying Association Rule Mining. The algorithm looks for sets of skills that often appear together and determines which rules can be deducted from these ‘shopping baskets’. These rules are recalculated daily and integrated into the Sk!lld search engine. This lowers the threshold to add relevant skills to a user profile or to find related profiles. We once again used R to implement the Association Rule Mining algorithm, this time with the arules package.
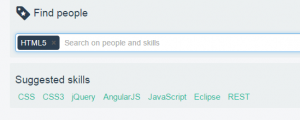
And that’s it. All in all it took me about one and a half days, with most time spent on cleaning the data. It’s been a while since I’ve done this extraction in early 2015, but I would still use most of the same tools today as I did then (with the exception of Python/Go/bash instead of R/Powershell, as I’ve been using them more often for scripting since writing this).
Special thanks to Davy Sannen for his help creating this post.
