This week I attended the software engineering conference QCon in London. Like last year, I noticed a further trend in moving away from more shiny tools! towards how to more effectively guide teams to deliver value (using whatever tools). Here are my main take-aways on the themes which resonated with me the most: building resilient systems for humans, building high performing teams and whether or not your frontends are safe from the microservices virus.
Creating high performing teams
There seemed to be more interest in engineering culture than before, and the topic of creating high performing teams received its own track. We’ve come to better realize that the specific tools don’t matter as much as the team and its focus on delivering real impact to end-users.
In ‘Secrets of a strong engineering culture’, Pat Kua elaborates on how to create an engineering culture that will attract engineers and help them grow. The three secrets are: make sure your engineers can see the impact of their work, they have a choice in coming up with a solution and your company can help them grow. Want to have an idea on how your current engineering culture performs? Ask yourself the following questions:

Especially the topic of giving engineers a choice in their technology will prove to be difficult for most organizations. Too much freedom can result in the company having to support too many different tools, but heavyweight rules and change advisory boards (which may look more as risk management theaters) will impact your engineering culture. Cultivate choice by making the right thing easy: automate the basics, prefer principles over rules, define the goal and get out of the way and define clear decision-making boundaries.
Gather input from everyone on how you can improve these elements, create a tech culture handbook and publish this for the world to know. Prioritize the key improvement areas, and do follow up on your actions.
To get a better idea of what the key improvements are, Tim Cochran of Thoughtworks shared some developer effectiveness metrics. Which different tasks are developers occupied with on a daily basis, and how long do they take? It could be onboarding a new team member, to launching a new service, validating a component in a dev environment or that it integrates with other services and so on.
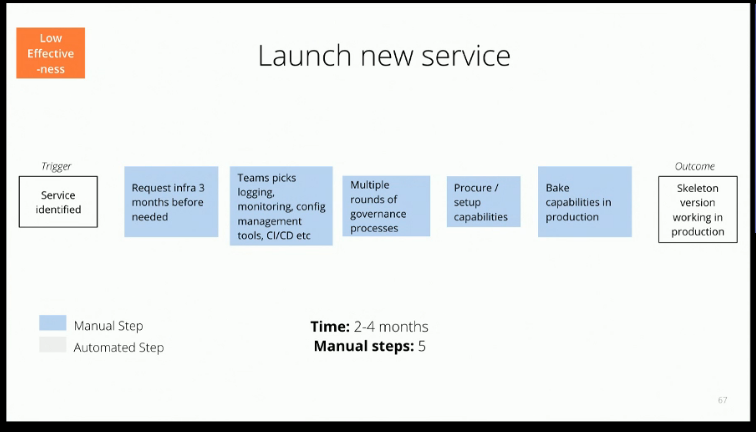
For any of these tasks, map the process and come up with a couple of leading indicators. What would a dev day look like in a highly effective environment?
How long does it take before a new member is productive? How long would it take to get a change approved in the Change Advisory Board? How many tickets are created to complete a process? How long does it take for a low effective team to launch a new ‘hello world’ service, vs. a high effective team?
(If your organization is on the ‘couple of months’ end of the scale vs. ‘a couple of days’, that’s also a leading indicator that your organization is not mature enough yet to handle the increased deployment complexity of microservices.)
This gives you an idea on where you can work on the process to make everyone more effective (and as a result, more motivated and happy).
Although if you do get there, and become a high performing team — it’s not always roses & peaches. One of my favorite talks which rang painfully true was ‘My team is high performing, but everyone hates us’, from Stephen Janaway.

High performing teams don’t last forever, they make mistakes. The organization changes, sponsors of your project may leave and once that happens — if you haven’t build up trust with the entire organization, you’re going to have a hard time.
Resist the temptation to focus inwards and ignore the ‘outside world’ and find a way to open up your team and sell it better. And as your team changes, revisit what works well and doesn’t work well for your team.

Build resilient systems because — not despite — of the humans
One of the key messages which popped up across several talks was that as our systems grow more complex (thank you microservices, but also the scale at which we operate and turn everything into software with more teams involved), it’s become more difficult or nearly impossible for us humans to completely understand the underlying systems. This creates confusion among the people building, maintaining or monitoring the system — and increases the time needed to resolve issues.
So how can we design our systems more for the humans and make them more resilient?
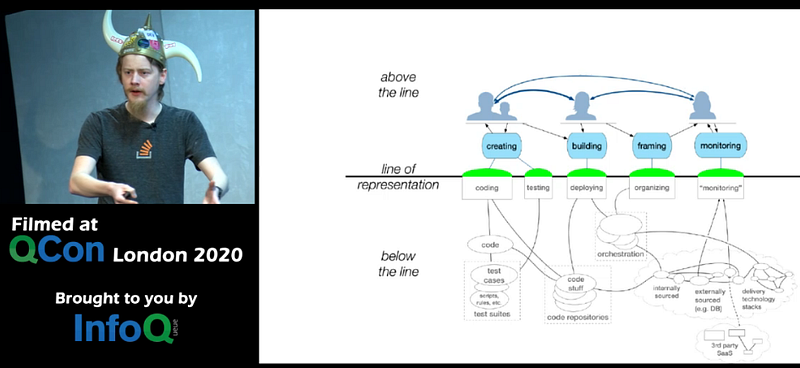
Yes — we should automate and document as much as possible. However, humans will always be there to cover the unexpected ‘weird’ things. ‘Things which have never happened before, happen all the time’.
In ‘Preparing for the Unexpected’, Samuel Parkinson from ft.com shared their story of when the domain ft.com disappeared, and how they prepare their build teams to support these weird incidents. They run workshops where they replay old incidents with printed hand-outs of graphs and comments made at the time.
They split-up into different teams to approach this problem, and after a few moments ask the teams how they would proceed (what’s the impact? what more info do you need?) and what they would communicate to business. This creates an operations mindset (limit impact, communicate) into engineers, who tend to dive into code straight away. The team also get a better sense of the entire system (‘below the line’), how to use the tools to diagnose incidents and think along on how to improve the system.
If you’re not running blameless post-mortems already, it’s a great way to start. However, don’t just focus on creating a timeline of all the events. Denise Yu (Why are distributed systems so hard?) and Randall Koutnik (Better resilience adoption through UX) added more questions you should ask during this process, such as
What seemed reasonable at the time for the humans involved in the process? And what were the other humans doing at this time?
While it’s great to have automation and documentation at hand, the team loses sight of everything that’s involved in the automation and engineers don’t read documentation — so keep in mind to design your systems and processes for humans. And when in doubt as to what the humans would do, just ask them and present a mock-up design.
The next frontier of microservices: the frontend
As microservices have conquered the thought-space of about every company, they start to look at the next frontier: what about our frontends?
As Ben Sigelman warned last year, there’s only one good reason to adopt microservices: achieve independence and velocity for your teams.
This holds especially true for the frontend. Whereas with back-end services you could achieve architectural features by splitting up (scaling differently, running a process in an event flow, shift a process to a managed serverless offering … ) this doesn’t hold true for the frontend, where you have to merge these different components back into a single unit in the browser. So if your pain point is not organizational structure, tackle your real problems first. For those who do suffer on that end, this is what you could do:
In ‘Lessons From DAZN: Scaling Your Project with Micro-Frontends’, Luca Mezzalira shared the foundations of how you could split your frontend to scale up your project based on different factors:
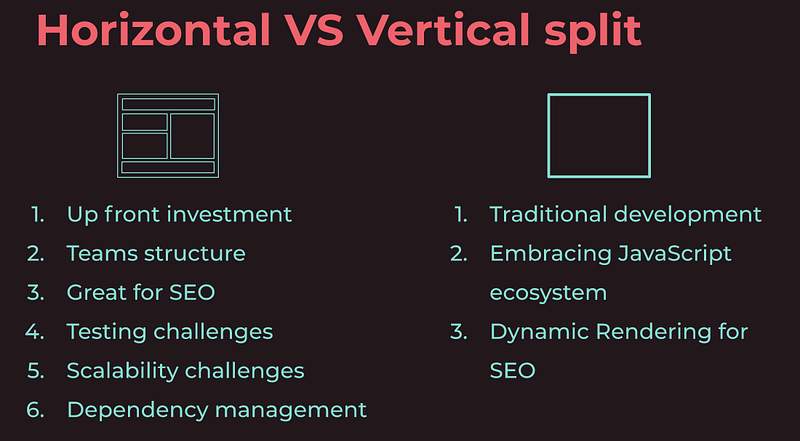
- Application split: horizontally (different frontends in the same view) or vertically (link to different views).
- Where to assemble all the pieces: At the CDN (e.g. Edge Side Includes), the origin server (e,g, server-side rendering) or at the client (via an orchestrating component)
‘There is no right or wrong, but only the right approach based on the context’.
Interestingly enough, they don’t use WebComponents to apply these splits. WebComponents allows you to use different frameworks or framework versions for the different components, but as it’s new the integrations aren’t completely mature yet for all the frameworks.
One final warning from Luca: don’t go overboard, some duplication can at times be better than the wrong level of abstraction. For example, the simple footer message is duplicated across all the DAZN sites, and only had to change once in two years — which took just a few moments. They could have created a component out of this, which would have increased the complexity to maintain the component, deploy the changes and test / communicate changes.
That’s it for my main takeaways from the conference, hope you enjoyed the short read. I had a blast and have to especially commend the organization: the hygiene practices ensured only good ideas and discussions went viral.
If you’re interested in more conference recaps from the past year, I have got a Qcon London ’19 and CraftConf ’19 for you in stock.
