The QCon Software Development Conference took place this week in London. Three days of interesting talks left me with a lot to digest, here are my takeaways on the recurring themes of the conference.
How to use your shiny new toys right
The organizers of the event, InfoQ, choose to focus the content on the topics they consider to be in the Innovator and Early Adopter stages of the software adoption graph. The latest version of their graph looks like this:
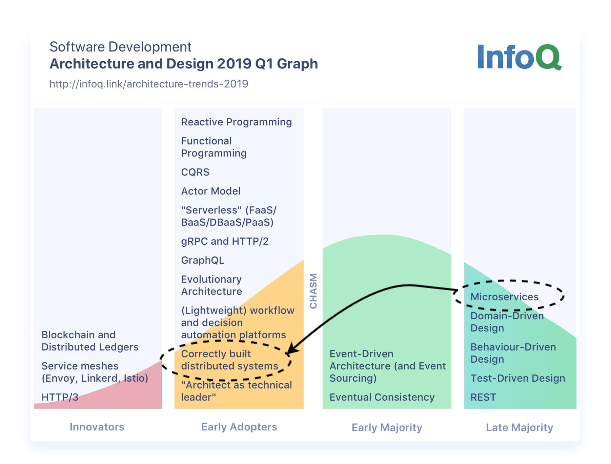
One of the main recurring themes of the conference was that yes, microservices are old news — but building them correctly is only done by early adopters. Another was that we have seen a lot of new shiny tools and methodologies the past few years in microservices and DevOps space, this year represented more of a consolidation year with fewer shiny tools presented and a renewed focus on best practices and culture.
So how do you build a distributed system correctly?
Choosing when (not) to microservice
One of the more popular talks was ‘What We Got Wrong: Lessons from the Birth of Microservices’ (slides, talk) by Ben Sigelman, former Googler (worked on Dapper) and now CTO of a tracing SaaS company. He notes there are only two reasons for adopting microservices at all:
- Accomplish incredible “Computer Science!” feats
- Achieve independence and velocity for your teams
Which means there’s only one reason left if you’re not striving for incredible technical feats like Google did (sometimes unnecessarily in his opinion, I’ll get back on that later): team velocity.
Despite all the technical innovation over the years, we remain terrible at scaling human communication. Teams are no longer effective beyond a dozen developers, which means you need to split them up and create new communication channels. Organizing a monolith release over multiple teams is a cumbersome process. Microservices help you release more often by placing services completely under the control of one team and removing friction to release.

This is what helped The Financial Times release 250 times more often and at a lot lower failure rate with their adoption of microservices. Sarah Wells from the FT posed the question that if you aren’t releasing multiple times a day or experimenting more often, consider what’s stopping you.
Ben’s assertation means that if you are not doing microservices for this reason (and e.g. deploying multiple services under just one team), you’re needlessly increasing the things that may go wrong and the operational complexity of your infrastructure.
Another downside of a microservices achitecture is that the narrow scope of understanding which helped you release more often may come back to bite you. A downstream service may become overloaded through a release in another service which increased its traffic ten-fold. Spotting this problem means you need better guided tracing approaches to observe the whole picture and understand the new ways in which things may go wrong.
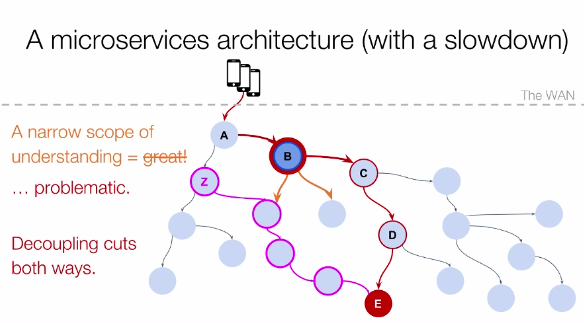
They are fair warnings and things to keep in mind when splitting up your infrastructure. I think you are fine releasing multiple services under one team if they serve more humble ‘computer science feats’ such as using different resource or scaling needs and you have a well automated testing and deployment infrastructure. Definitely don’t go overboard. I prefer the ‘elegant-monolith-first’ approach and split when a good reason presents itself and the business domain is well understood at that point, to avoid prematurely splitting up a service and making it more difficult to reshape the communication patterns later. For some organizations, getting more services results in more release and governance trouble, for others the cost of splitting up a service may be small. In case of the former, Ben’s guidelines may prevent you from shooting yourself in the foot.
Platform choice for microservices
With teams in charge of their own services, which platform should you use for your microservices?
Sarah Wells cited a quote from Accelerate, about one of the important indicators of high performing teams:
High performing teams get to make their own decisions about tools and technology
This makes the teams happy and removes the wait for decisions from an architecture review board. Allowing multiple options also accepts the fact that one size does not always fit all: which was one of the mistakes Ben noted Google made in trying to get every product match the needs of the Search+Ads team — and try to achieve both high throughput and low latency at all costs.
But delegating tool choice to teams make it hard for central teams to support everything. Teams will make different decisions and it needs to be clear they are in charge of running the software. For Sarah this means relying as much as possible on managed services and making the run someone else’s problem. Ben drew a chart based on the moral perspective alignments of Dungeons & Dragons:
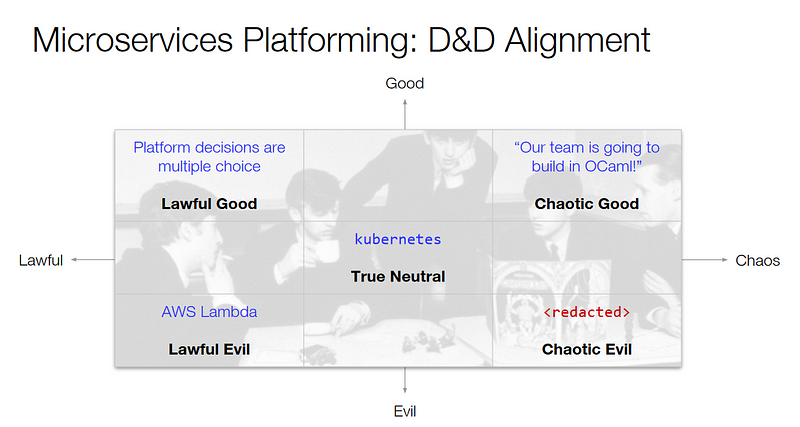
Where the lawful good choice is to make platform decisions multiple choice. If a team wants to use something new, allow them — but make sure they know what’s needed in order to make it a supported paved road in the organization and integrate with the central monitoring tools and so forth.
Ops & Culture
So how are correctly built distributed systems monitored and operated?
More services and network calls will result in more failures. Not all of these failures are equally important or even have an effect on the end-user at all. To ensure their ops engineers remain sane and enjoy sufficient enough sleep, Sarah Wells and Liz Fong-Jones (slides) offered the following advice:
Don’t focus on too many things with a slew of dashboards. Monitor the 3 golden signals:
- request rate
- latency
- error rate
and define a Service Level Objective for what’s acceptable for your product. Don’t know where to start and which number to pick? Measure how you do today on these factors, set them as your SLO and start to monitor the variance on these signals. If you can not explain why the variances occur, put more effort in making your application flows better observable.
Decide on an error budget (how many errors / degraded experiences do you allow per month), and only page your engineers when it looks like your error budget is going to be exceeded soon (either through failures accumulated over time or a sudden sharp consistent increase). Deciding on an error budget as a team also allows you to prioritize feature stories vs. refactoring/fixing and present a business case for the latter.
Don’t invest too much in runbooks, focus more on automation. Every failure is a novel state, which you probably did not presciently note in your runbook. Ensure you can discover what went wrong quickly, mitigate the issue immediately and work on automating the fix later.
Thoughts on Functions as a Service (FaaS) / Serverless
Track host Sam Newman mentioned serverless as the logical next step for cloud computing. Critics like Ben called Jeff Bezos the apex predator of capitalism and cited how wasteful functions are: main memory reference has a latency of about 100 ns. A round trip within the same datacenter: 500,000 ns. There was however one different approach presented which even he agreed made a lot of sense to use.
Cloudflare, a CDN company, offers a FaaS model where your functions run in the JavaScript v8 engine hosted on of their 165 edge locations. Instead of spawning a docker process for a function invocation, Cloudflare’s approach is more akin to starting a new tab in a browser though an isolate feature of v8. This results in a cold startup time of a few ms, compared to seconds with what AWS, GCP and Azure offer. Running workers on your edge locations also means your latency remains low and it runs exactly at the point where traffic just enters or leaves to your customer with data. Sending responses to the user without the proper security headers set? Strip credit card information or internal server errors in a filter? Add them through a worker with little overhead. Show different content or route traffic to a different server for A/B testing? Makes sense to put that in your CDN entry point. Cloudflare workers offer different use cases than gluing cloud services together on one of the big cloud providers, without the cold-start downside.
With both models of FaaS, you do need to evaluate the costs and benefits up front and make it a conscious and calculated decision. What kind of queries will you run, what would the cost structure look like for your usage and is the expected latency acceptable? You could replace your entire back-end with Lambda as Bustle have done, but it may not work out for (portions of) your infrastructure. For my smaller projects I love the low cost and managed aspects of FaaS and remain more hopeful like Sam.
Parting thoughts
I did attend sessions on the status of general artificial intelligence, NLP word embeddings and quantum computing; but what I found most fascinating instead was a talk from Chris Ford where he demonstrates how music theory can be represented as code. It was absolutely delightful and a good explainer on pitch and harmony too. “Literature conferences are not about typesetting and more about the art — why can’t software conferences be more about the art of code?” he wondered and proceeded to jam on stage with his musical functions.
A good closing talk to head home to afterwards, with more to think about and explore on other topics like reactive architecture, workflow orchestration and service communication patterns which I haven’t digested yet and may include in a new post. These were the main themes I saw throughout the conference, hope you enjoyed this write-up.
